‘The half minute which we daily devote to the winding-up of our watches is an exertion of labour almost insensible; yet, by the aid of a few wheels, its effect is spread over the whole twenty-four hours.’
From the previous entry in this series, one of the things of note in
discussing the nature of the connections between LISP and (the) lambda
calculus was John McCarthy’s concern about recursion and higher-order
functions.
A couple of excerpts from previous quotes from McCarthy on the subject
to set the stage:
…And so, the way in which to [be able to handle function passing/higher
order functions] was to borrow from Church’s Lambda Calculus, to
borrow the lambda definition. Now, having borrowed this notation, one
the myths concerning LISP that people think up or invent for
themselves becomes apparent, and that is that LISP is somehow a
realization of the lambda calculus, or that was the intention. The
truth is that I didn’t understand the lambda calculus, really. In
particular, I didn’t understand that you really could do conditional
expressions in recursion in some sense in the pure lambda calculus.…
…Writing eval required inventing a notation representing LISP
functions as LISP data, and such a notation was devised for the
purposes of the paper with no thought that it would be used to express
LISP programs in practice. Logical completeness required that the
notation used to express functions used as functional arguments be
extended to provide for recursive functions, and the LABEL notation
was invented by Nathaniel Rochester for that purpose. D.M.R. Park
pointed out that LABEL was logically unnecessary since the result
could be achieved using only LAMBDA — by a construction analogous to
Church’s Y-operator, albeit in a more complicated way.…
Recursion is a concept or process depends on a simpler or previous
version of itself. It’s ubiquitous, including in the natural world:
Wikipedia notes that “Shapes that seem to have been created by
recursive processes sometimes appear in plants and animals, such as in
branching structures in which one large part branches out into two or
more similar smaller parts. One example is Romanesco broccoli.”
Figure 1: Romanesco broccoli (Brassica oleracea), from Wikipedia
Recursion is a thing I deal with a lot in my day job, as it is a
feature of natural language, especially syntax and semantics. To
provide a quick illustration — though this is not at all how modern
generative syntax is done anymore — consider phrase structure grammar
and phrase structure rules used by Noam Chomsky and his colleagues in
the 1950s.
Sentences (and linguistics objects generally) have formal structure,
and it is part of the productive/creative nature of language that we
might envision this structure as involving abstract structure rules
that can be expanded in different ways (and then have vocabulary
filled in).
A phrase structure rule will generally have the form A → [B C],
indicating that A may be rewritten or expanded into [B C]. (In the
following, I’ll use round brackets ()'s to denote optional
constituents.)
So, a subset of these rules for English might include something like
(note that some things have multiple rules that can apply to them):
Code Snippet 1:
a snippet of phrase structure grammar rules for English [Nb.: again, not prolog, but maybe the best fontlocking choice here]
(Where S is “sentence”; Det is a determiner (like “the”, “a”); NP is a
noun phrase; Nₙ is a noun head; AdjP is an adjective phrase; VP is
a verb phrase; V is a verb head; CP is a complementiser phrase; Comp
is a complementiser (like “that”).)
So we can rewrite S as NP VP (1) and then rewrite NP VP as Det N VP
(2, choosing an optional Det) and then Det N VP as Det N V (4) and then
insert lexical items of the appropriate category into the ‘heads’ (the
non-P elements). So we might choose “the” for Det and “cat” for N and
“purrs” for V, and get the sentence “the cat purrs”.
But note that some of the rules allow for expansion into elements that
contain expansions back into themselves. So rule (1) allows an S to
exapnd into NP VP and rule (6) allows for a VP to expand into V CP and rule
(7) allows for a CP to expand into an S. At which point we can apply
rule (1) again to expand the new S into NP VP, and then repeat this
process as many times as we like:
Code Snippet 2:
a recursive English sentence expansion [Nb.: again, not prolog, but maybe the best fontlocking choice here]
And it’s easy to imagine examples of what such a sentence could be
like, e.g., “John said that Sita said that Bill said that Mary said
that Ram said that Kim said that…". It won’t be infinitely long, but
there’s no particular theoretical bound on how long it could be
(memory processing and finite human lifespans will impose practical
limits, of course).
On the formal semantics side, things are similar: consider that
logical languages too (which are often used to formalise natural
language semantics) allow for recursion. Propositional logic
construction with Boolean operators too have no theoretical upper
limits: we can write (t ↔ (p ∧ (q ∨ (r → (s ∧ ¬¬¬¬¬¬t))))),2 and
there’s nothing which prevents composing this bit of formalism with
yet another bit, and so on.
And in mathematics and computer science, recursion is often a thing
which suggests itself.
For instance, though there are other ways of calculating it, the
Fibonacci sequence3, i.e., a sequence of numbers in which each
element is the sum of the two elements that precede it (e.g. 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144…).
A natural way of writing an equation to calculate these is something
like:
Fib(0) = 0 as base case 1.
Fib(1) = 1 as base case 2.
For all integers n > 1, Fib(n) = Fib(n − 1) + Fib(n − 2).
Rule 3 makes reference to itself. I.e., in order (by this method) to
calculate Fib(6), you have to calculate Fib(5), for which you have to
calculate Fib(4)), for which you have to calculate Fib(3), for which
you have to calculate Fib(2), which you can then base on rules (1) &
(2): you can add 0 and 1 (= Fib(0) and Fib(1)) together to get Fib(2),
and then you can calculate Fib(3) by adding Fib(1) and Fib(2) and so on.
In early Lisp(s), despite the concern around recursion, writing
recursive functions was/is not always pragmatically viable, because it
can lead to stack overflows (potential infinities are hard in
practice).
Scheme, a Lisp dialect originally created at MIT by Guy L. Steele, Jr.
and Gerald Jay Sussman, was the first Lisp to implement tail call
optimisation, which is a way of making significantly recursive
functions viable, making tail calls similar in memory requirement to
their equivalent loops.
Before talking (a little bit more) about tail recursion, let’s look at
concrete examples of a tail recursive function and its loop
equivalent. We’ve mentioned Fibonacci numbers already, so let’s try to
write functions calculate these (in Emacs Lisp).
Following the mathematical abstraction for the Fibonacci sequence
above, we could write a function like this:
;; -*- lexical-binding: t; -*-(defunfib1(nab)"Calculate the first `n' Fibonacci numbers, recursively."(if(<n1)a(consa(fib1(1-n)b(+ab)))))
Code Snippet 3:
a first go at a recursive elisp function for fibonacci numbers
I’ve tried to make this as simple as possible, we could make it nicer
(say, with a wrapper function or some some of flet) so that we didn’t
have to pass in the initial values. But, keeping it simple (for now):
fib1 is a function taking three arguments: n, the quantity of
Fibonacci numbers to return; a, the first number to start with; and b,
the second number to start with.
Following the schema above, we’re going to pass 0 for a and 1 for
b. Let’s get the first ten numbers of the sequence, and pass 10 for n:
(fib11001); (0 1 1 2 3 5 8 13 21 34 . 55)
I know, the output is a bit ugly because we’re just cons’ing the
results and so it’s not a proper list, but we’re keeping things
simple.
Let’s walk through how it works. The function first looks at n, if n
is less than 1, it returns a (whatever it is). If n isn’t less than 1,
we return the cons of a with the result of calling fib1 itself on “n
minus 1” b and “a plus b”.
So if we start with n=3, a=0, b=1, that is, evaluate (fib1 3 0 1), the
function would say, well, 3 isn’t less than 1, so I’m going to create
a cons with 0 and the result of calling (fib1 2 1 1) (2 = “n minus 1”,
because n is currently 3; 1 because b=1; and 1 because a + b = 0 + 1 =
1).
So at this point we have a cons that looks like this:
(0.(fib1211));; [= (cons 0 (fib1 2 1 1))]
When we evaluate (fib1 2 1 1), n is still not less than 1, so we’re
going to cons the current value of a (which is 1) with another call to
fib1: (fib1 1 1 2) (1 = “n minus 1”, because n is currently 2; 1
because b=1; and 2 because a + b = 1 + 1 = 2).
Now we have to evaluate (fib1 1 1 2). n is still not less than 1; so
we create another cons of 1 (as a is currently 1) with yet another
call of fib1: (fib1 0 2 3) (0 = “n minus 1”, because n is currently 1; 2
because b=2; and 3 because a + b = 1 + 2 = 3). And so now:
And, finally, evaluating (fib1 0 2 3), now n is less than one, so we
take the first branch of the conditional and just return a, which is
2. So the result of starting with (fib1 3 0 1) is:
(011.2);; [= (cons 0 (cons 1 (cons 1 2)))]
And you can try this with other values of n, e.g., try evaluating
(fib1 100 0 1) to get the first 100 members of the sequence.4
But, at least for me on Emacs 30.0.93, 529 is the limit. If we try
(fib1 520 0 1), the debugger pops up with a 1622 line long error,
which begins:
Code Snippet 4:
beginning of excessive-lisp-nesting error for our fib1 function
Because we’ve built up a long, deeply-embedded list of conses and
Emacs has a limit of how deep it’s willing/able to go (you can see
above that we’ve almost made it to the end, just needing to calculate
fib1(0), when Emacs decides it’s had enough).
In Scheme and elsewhere, self-recursive calls at the ends (“tails”) of
functions can be optimised to avoid these sorts of stack overflows
(excessive-lisp-nesting).5 Tail-call optimisation lets
procedure calls in tail positions be treated a specialised GOTO
statements, which can be efficiently processed:
…only in cases where structures are explicitly declared to be
dynamically referenced should the compiler be forced to leave them on
the stack in an otherwise tail-recursive situation. In general,
procedure calls may be usefully thought of as GOTO statements which
also pass parameters, and can be uniformly encoded as JUMP
instructions. This is a simple, universal technique, to be contrasted
with […] more powerful recursion-removal techniques…
Recursive functions are perhaps most idiomatic in Scheme (among lisps,
I mean). Some implementations of Common Lisp can do tail-call
optimisation, but loops are perhaps more common, and certainly in
Emacs Lisp (for reasons you can see above), loops are usually what are
used. And so we can write a new Fibonacci function with a loop. It
won’t be nearly as pretty, but it’ll work better.
Here’s one possible implementation:
;; -*- lexical-binding: t; -*-(defunfib2(nab)"Calculate the first `n' Fibonacci numbers,
in a loop."(let((resultnil))(dotimes(cn)(setqresult(consaresult))(setqtempab)(setqb(+ab))(setqatempa))(nreverseresult)))(fib21001); (0 1 1 2 3 5 8 13 21 34)(setqbigfib-50000(fib25000001)); this will work - we can get 50,000 numbers
Code Snippet 5:
a second go at a fibonacci function, with looping
The result is prettier at least: a proper rather than an improper list
(because we started by cons'ing onto an empty list). Our fib2 function
itself isn’t as mathematically pleasing as our fib1 function, we end
up with a lot of setq's (the nreverse at the end reverses our list,
because the way we build up our list is by cons'ing the first results
first, so they end up at the end until we flip them with
nreverse). But it works well. If you try to (fib2 100000 0 1), it’ll
fail, but not because of stack overflow, just because we end up with
numbers that are too big for Emacs. But you can certain get the over
50,000 members of the Fibonacci sequence, which is much better than
fib1's limit of 529.
And dotimes is just one loop procedure available. (See cl-loop for a more
powerful one.)
Ok, so, practically, we should probably generally prefer loops over
tail-recursive functions in Emacs. But, what if we just like the latter
more?7 Are there any other possibilities?
Wilfred Hughes has an emacs package tco.el which implements a
special macro for writing tail-recursive functions.8 It works by
replacing each self-call with a thunk, and wrapping the function body
in a loop that repeatedly evaluates the thunk. Thus a
function foo defined with the defun-tco macro:
And this delays evaluation in such a way as to avoid stack
overflows. Unfortunately, at least currently for me (Emacs 30.0.93
again), tco.el seems to have some issues.
;; -*- lexical-binding: t; -*-(defunfib3(n)"Calculate the first `n' Fibonacci numbers,
recursively, with limited tail-call optimisation
through `cl-labels'?!"(cl-labels((fib*(nab)(if(<n1)a(consa(fib*(1-n)b(+ab))))))(fib*n01)))(setqbigfib3(fib3397)); 396 highest that works
Code Snippet 6:
a third go at a fibonacci function, with cl-labels
At least the way I’ve written it, it seems to suffer an overflow even
sooner (at 397 rather than 529 as for our fib1), because it has to
come back and do the cons after the tail-call — so fib* isn’t actually
in the tail. (We can fix this in at least one way, which we’ll do in fib5.)
We could try to write an accumulator as a hack, where we try to do
ours conses one at a time and pass along the results, but this fares no
better than our fib1:
;; -*- lexical-binding: t; -*-(defunfib4(nabaccum)"Calculate the first `n' Fibonacci numbers, recursively,
but collect conses as we go and keep track of the length of
the `accum' cp. against `n'."(let*((accum(consaaccum))(accum-lng(lengthaccum)))(if(<naccum-lng)(nreverseaccum)(fib4nb(+ba)accum))))(setqbigfib4-529(fib452901nil)); last good(setqbigfib4-530(fib453001nil)); overflows
Code Snippet 7:
a fourth go at a fibonacci function, with an accumulator
If we combine cl-labels and the accumulator trick, however, we do seem
to be able to escape stack overflows, because now we’ve got fib*
properly in the tail:
;; -*- lexical-binding: t; -*-(defunfib5(n)"Calculate the first `n' Fibonacci numbers, recursively,
using both cl-labels and the accumulator trick."(cl-labels((fib*(abaccum)(let*((accum(consaaccum))(accum-lng(lengthaccum)))(if(<naccum-lng)(nreverseaccum)(fib*b(+ba)accum)))))(fib*01nil)))(setqbigfib5-10000(fib510000)); ok(setqbigfib5-50000(fib550000)); very slow, but ok
Code Snippet 8:
a fifth go at a fibonacci function, with cl-labels and an accumulator
Now we’re back in the realms of what our fib2 non-recursive loop-style
function could do. Although (setq bigfib5-50000 (fib5 50000))
calculates very slowly (worse than our looping fib2), so that’s not ideal.
But here’s another possibility: Nicholas Pettton‘s stream package
for emacs, where “streams” are delayed evaluations of cons cells.
;; -*- lexical-binding: t; -*-(defunfib6(n)"Return a list of the first `n' Fibonacci numbers,
implemented as stream of (delayed evaluation) conses."(cl-labels((fibonacci-populate(ab)(stream-consa(fibonacci-populateb(+ab)))))(let((fibonacci-stream(fibonacci-populate01))(fibsnil))(dotimes(cn)(setqfibs(cons(stream-popfibonacci-stream)fibs)))(nreversefibs))))(setqfib6-10k(fib610000)); ok(setqfib6-50k(fib650000)); little slow, but works(setqfib6-100k(fib6100000)); little slow & overflow error
Code Snippet 9:
a sixth go at a fibonacci function, with delayed evaluation conses
This works well. (fib6 50000) still turns out to run a bit slower than
our (fib2 50000), so loops are still probably more efficient, but
streams are pretty interesting. They can can used to represent
infinite sequences. So here, above, fibonacci-stream (set by
(fibonacci-populate 0 1)) is actually an infinite stream of Fibonaccis
numbers, but lazily evaluated, so we just get the next one each time
we call stream-pop on our fibonacci-stream local variable. (What
happens is that stream-pop takes the car of fibonacci-stream,
evaluates and returns it, and then sets fibonacci-stream to be its cdr
(i.e., popping off and “discarding” the first element; which which
captured in our fibs collector.))
I had hoped to get to the Y Combinator today (and think I might have
suggested a promise of that), for that’s where things really get
interesting. And we need to get back to lambda calculus, of course.
But we may be near the limits of excessive lisp nesting ourselves
here.
However, the recursion discussion here has set the stage for the Y
Combinator, which we’ve already talked a couple of times, especially
in connection to John McCarthy’s claims about “not really
understanding” lambda calculus and the fact that these really centre
on his not seeing how one could get recursion without direct
Self-reference (and thus the need for LABEL) because of not knowing
about the Y Combinator.
And, the Y Combinator ties in with all sorts of other curious
things. Paradoxes, types, calligraphy.
[Thus, I ended up with an excursus on this excursus as the next
post. I’ll put a link here to the proper third part when it’s up.]
McCarthy, John. 1978a. History of Lisp. In History of programming languages, ed. Richard L. Wexelblat, 173–185. New York:
Association for Computing Machinery. https://dl.acm.org/doi/10.1145/800025.1198360↩︎
“t if and only if p and q or if r then s and
not not not not not not t” ↩︎
A number of Indian philosophers, at least as far back as
Virahāṅka (ca. AD 600–800), gave formulations for what is usually
called the Fibonacci sequence. See Singh, P. (1985). The so-called
fibonacci numbers in ancient and medieval India. Historia Mathematica,
12(3), 229–244. https://doi.org/10.1016/0315-0860(85)90021-7 [pdf] ↩︎
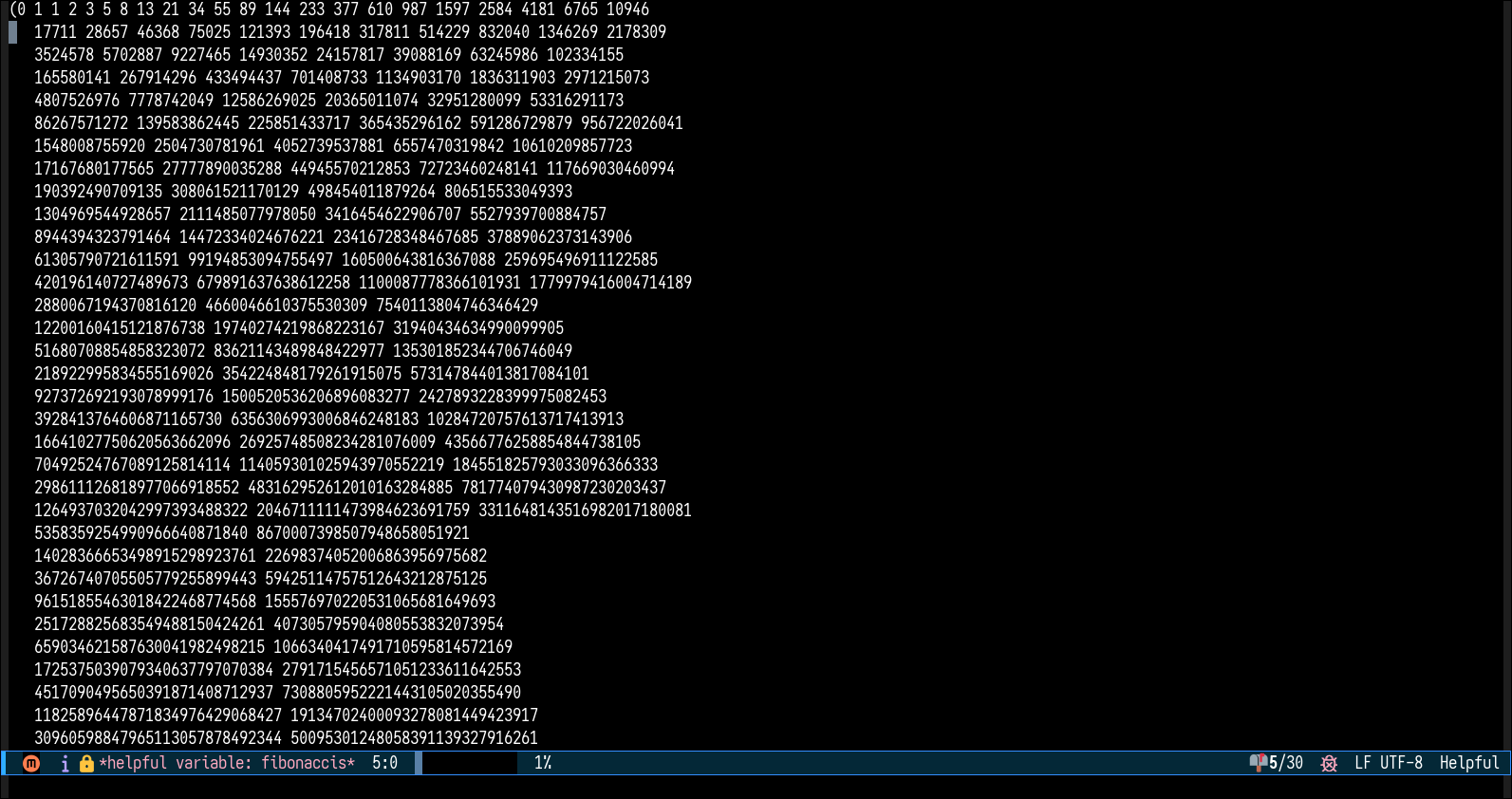
You might actually want to do something like (setq my-fib1-100 (fib1 100 0 1)) to put the result into a variable, because
the echo area at the bottom of Emacs isn’t big enough for all of the
numbers. (Oh, to eval things in an Emacs buffer, put your cursor/point
at the end of the expression and press C-x C-e. But don’t do that for
this one. If you want Emacs to just stick the results in directly into
the buffer rather than echoing them, press C-u C-x C-e. But don’t do
that here either, because Emacs will still end up printing an ellipsis
because it thinks it’s too long.) And then press C-h v and type
my-fib1-100 and enter to see the result. ↩︎
See further here, for instance, for more about tail calls and
tail call optimisation. ↩︎
Steele, Guy L., Jr. 1977. Debunking the “expensive procedure
call” myth or, procedure call implementations considered harmful or,
LAMBDA: The Ultimate GOTO. ACM ‘77: Proceedings of the 1977 annual
conference, 153–162. [https://dl.acm.org/doi/10.1145/800179.810196] ↩︎
If you’ve read any of Paul Graham’s Common Lisp books
(e.g., On Lisp) or any of the Little Schemer books (the latter with
Duane Bibby‘s lovely artwork in them), you may be disposed towards
using recursion rather than loops.
Figure 4: close-up of Duane Bibby’s cover illustration for “The Little Schemer”